Извлекаем комментарии
Возвращаемся на вкладку «Elements» в Chrome и находим там контейнер, в котором хранятся все комментарии.
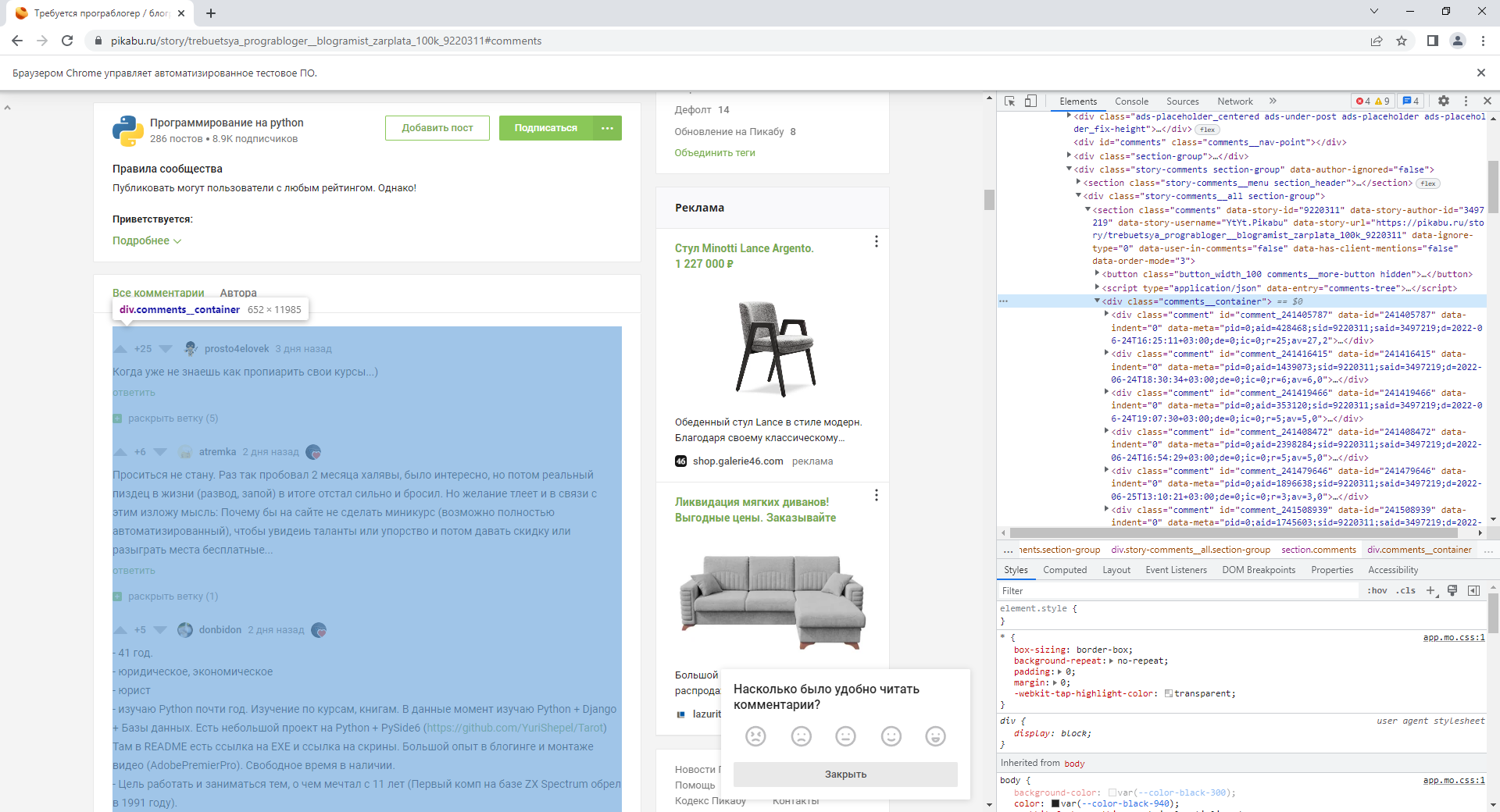
Извлекаем содержимое этого контейнера и собираем из него удобную структуру данных с помощью BeautifulSoup.
comments_container = driver.find_element(By.CSS_SELECTOR, 'div.comments__container')
comments_container_html = comments_container.get_attribute('innerHTML')
soup = BeautifulSoup(comments_container_html, features='html.parser')
Извлекаем из каждого комментария текст и информацию об авторе. Интересны только первые комментарии, поэтому рекурсивно погружаться внутрь ветки не будем.
comments = soup.select('div.comment__body')
comments_content = []
for comment in comments:
user_name = comment.select('div.comment__user')[0]['data-name']
user_link = comment.select('a.user')[0]['href']
body = '\n'.join(comment.select('div.comment__content')[1].stripped_strings)
comments_content.append({
'user_name': user_name,
'user_link': user_link,
'body': body
})
Теперь у нас есть список словарей, в котором хранится юзернейм, ссылка на пользователя и текст его комментария.